Avant toute chose, des exemples de commandes sont données dans ce tutoriel. Afin de mieux identifier l’environnement dans lequel on se trouve, des invites (prompts) ont été utilisées.
Par exemple si on lit :
hôte> echo "toto"Il faut ignorer la partie à gauche hôte>, on trouvera dans la suite l’invite container> qui est à ignorer de la même façon. La commande à taper est donc simple echo "toto".
Pourquoi ?
On a parfois la nécessité de travailler avec certaines versions de logiciels et de bibliothèques et de faire cohabiter ces différentes versions sur une même machine. Selon les logiciels, la recette est plus ou moins aisée. Pour Python par exemple, on utilise souvent conda pour confiner les bibliothèques. Pour des compilateurs, etc. c’est souvent plus délicat…
Docker une solution ?
Docker est un logiciel de conteneurisation. C’est-à-dire fournit à un ensemble logiciel le moyen de s’isoler proprement du reste de la machine hôte et donc libère des manipulations plus ou moins complexes, voire quasi-impossibles, de réaliser cela par des moyens traditionnels (jeu sur le nommage des fichiers et des commandes, utilisation abusive de variables d’environnement, etc.). Un conteneur fonctionne comme une machine autonome, correctement isolée de la machine qui l’accueille. Un conteneur est comme une machine sur laquelle on aurait installé que les logiciels nécessaires pour une tâche donnée.
Installation d’un environnement
Dans la suite, et pour notre exemple, on installera un «Docker» pour exécuter du code Python3.9 utilisant la bibliothèque spaCy sous Ubuntu 20.04.
Préliminaires
Il faut tout d’abord installer sur sa machine hôte le logiciel Docker, le logiciel de conteneurisation. En général, la procédure d’installation permet et encourage le test du logiciel; il vaut mieux s’y conformer.
MacOS
Le lien de téléchargement et la procédure d’installation sont ici. Le logiciel correspondant est Docker Desktop.
Windows
Le lien de téléchargement et la procédure d’installation sont ici. Le logiciel correspondant est Docker Desktop.
Linux
Le lien de téléchargement et la procédure d’installation sont ici. Le logiciel correspondant est Docker Engine. L’installation est plus brute, elle nécessite d’employer le terminal et une série d’apt install. Pour info, apt est une suite logicielle de gestion de packages. Un package est un ensemble de fichiers constituant la distribution du logiciel correspondant, il s’agit souvent de commandes ou de bibliothèques. La difficulté est liée à la gestion des dépendances que les logiciels ont entre eux et le système (version compatibles, etc).
Préparation
Installer un Docker, ou plutôt installer une image Docker consiste en la fabrication de l’image d’un système tel que le voudrait. C’est-à-dire quel système, quelles suites logicielles, etc. La définition de cette image passe par un fichier de description. Un simple fichier texte contenant des directives. Habituellement, ce fichier est nommé Dockerfile mais peut porter un nom quelconque.
Description de l’image : le Dockerfile
Voici un «Dockerfile» :
FROM ubuntu:focal
RUN apt update
RUN apt upgrade
RUN apt -y install python3.9
RUN apt -y install python3-pip
RUN python3.9 -m pip install spacy
RUN python3.9 -m spacy download en_core_web_smCelui-ci est assez simple. Il est constitué de deux parties.
FROM
La première (ligne 1) permet de spécifier le système d’exploitation qui sera utilisé pour l’image Docker. Une image Docker représentant une suite logicielle dans un système particulier, il est nécessaire de le spécifier.
Ici nous avons donc choisi de construire l’image à partir d’Ubuntu 20.04 dont le petit nom est Focal Fossa. C’est une distribution Linux très répandue au moment de l’écriture de ce tutoriel. Ce n’est pas la plus récente mais c’est la dernière dite LTS, Long Time Support, c’est-à-dire pour laquelle la stabilité, la qualité, etc sont assurés pour une longue période (5 ans pour celle-ci).
RUN
La seconde est une suite de directive RUN qui permettent d’exécuter des commandes à l’intérieur de ce système de base une fois que l’image de base a été chargée (il existe un dépôt central de nombreuses images Docker, le Docker Repository). C’est comme si on installait le système «nu» minimal et qu’on y installait ensuite des logiciels.
La première et la seconde (ligne 3 et 4) permettent donc mettre à jour le gestionnaire de paquets. Celui-ci étant lui-même un logiciel il est plus prudent de le mettre à jour. Donc on met à jour le gestionnaire (update) puis on demande de mettre à jour les paquets déjà installés (upgrade).
La troisième (ligne 5) permet d’installer python3.9 ainsi que tout ce qui est nécessaire à son fonctionnement. C’est-à-dire d’autres paquets (toutes les dépendances). Ils peuvent être assez nombreux. La commande apt est normalement interactive, c’est-à-dire qu’elle converse avec l’utilisateur en l’interrogeant de temps en temps sur le bien fondé d’une opération (êtes-vous sûr ? etc.). Évidemment, puisqu’il s’agit ici d’automatiser le processus, il n’est pas raisonnablement envisageable d’interroger l’utilisateur durant la procédure. C’est pourquoi l’option -y est utilisée, celle-ci permet de répondre automatiquement yes à toutes les questions qui pourrait être posées.
La quatrième (ligne 6) permet d’installer pip, le gestionnaire de bibliothèques Python. Oui Python possède son propre gestionnaire de bibliothèques (Python donc). Puisque nous installons python3.x, il s’agira de pip3.
La cinquième (ligne 7) permet d’installer dans l’environnement Python3.9 la bibliothèque spaCy (ici aucune version n’est précisée mais la dernière le sera (une 3.x aujourd’hui).
Et enfin la sixième directive (ligne 8) qui permet d’installer dans spaCy le pipeline de calcul pour la langue anglaise.
Installation de l’image
Pour créer l’image et l’installer dans l’environnement Docker, il faut utiliser une commande comme celle-ci :
hôte> docker build -t focpyt3spacyen -f Dockerfile .docker est le nom de la commande à invoquer pour réaliser une opération «sous Docker».build est la paramètre qui permet de construire une image.
L’option -t et la valeur associée focpyt3spacyen, permet de spécifier le nom que l’on souhaite donner à cette image. En effet, on peut disposer d’autant d’images que nécessaire (un avec python3, une autre avec perl, etc). On a choisi ici un nom un peu cabalistique, mais peu importe, n’importe quel nom est utilisable.
L’option -f et sa valeur associée Dockerfile n’est pas strictement obligatoire. Elle est donnée pour l’exemple. Elle permet de spécifier le nom du fichier décrivant la construction à réaliser. Si l’on ne positionne pas cette option le fichier Dockerfile sera utilisé. C’est donc clairement redondant ici.
Enfin le paramètre . sert à spécifier le répertoire dans lequel le fichier de description de l’image est présent. . est une valeur permettant de représenter le répertoire courant, celui dans lequel on est placé au moment où l’on lance la commande, mais n’importe quelle valeur est acceptable.
Cette commande prend un certain temps car il est alors bien souvent nécessaire de télécharger depuis divers sites les logiciels : le dépôt des images de base comme Ubuntu, les paquets Linux, les bibliothèques Python, etc. De plus, l’installation dans l’image requiert un certain temps. En général cela produit un résultat très verbeux. Y sont décrites toutes les étapes essentielles et les décisions prises lors de la construction.
Si la construction réussit une image de nom indiqué est créée, ce que l’on peut vérifier avec la commande suivante :
hôte> docker imagesqui produit alors un résultat comme :
REPOSITORY TAG IMAGE ID CREATED SIZE
focpyt3spacyen latest b9c8a941fb42 16 minutes ago 808MB
ubuntu focal 7e0aa2d69a15 7 days ago 72.7MB
wordpress latest aeb0c3e39096 7 weeks ago 551MB
mysql 5.7 d54bd1054823 2 months ago 449MBOn observe ici que l’environnement Docker contient 4 images. La première étant celle que nous venons de construire : focpyt3spacyen. La troisième colonne est l’identification Docker de cette image, ce par quoi l’image est identifiée de façon unique. En effet le nom sous la forme de caractères n’est qu’un raccourci plus facile à manipuler par les humains.
À partir de là nous avons enfin de quoi travailler…
Tester si l’image fonctionne
Une image Docker n’est juste rien de plus qu’une machine prête à être employée. Pour l’utiliser il faut exécuter cette image, un peu comme démarrer l’ordinateur qui en serait doté. Une telle exécution est un container. Il faut immédiatement noter que ‘on peut exécuter plusieurs container éventuellement en même temps de la même image.
La commande de base est docker run, que l’on doit éventuellement agrémenter de divers paramètres. Un premier test serait :
hôte> docker run focpyt3spacyen dateLe troisième argument est le nom de l’image, ici (focpy3spacyen) on peut utiliser le nom en lettre ou l’identifiant unique.
Le quatrième paramètre et les suivants constituent la commande à exécuter à l’intérieur du container. Ici nous nous contentons de demander la date courante dans le container.
Une commande à exécuter et qui comporterait plusieurs arguments pourrait être :
hôte> docker run focpyt3spacyen date --date='TZ="America/Los_Angeles"'Ici, donc, à partir du quatrième argument (date --date='TZ="America/Los_Angeles"'), tout est transmis pour exécution au container qui l’interprètera comme si on avait la machine correspondante sous la main et qu’on entrait cette commande au clavier. Ici l’obtention de la date et heure courante dans le fuseau horaire de Los Angeles.
Tester le mode interactif
Il faut noter que les tests précédents consistent en l’exécution de chaque commande dans un nouveau container. C’est-à-dire qu’une fois l’exécution terminée, le container disparaît. Attention ceci a une conséquence très importante : les modifications du système qui auraient été apportées dans une exécution ne sont pas rapportées dans l’image!!! L’image est un point de départ stable. Il est possible d’obtenir une image à partir d’une exécution modifiée mais cela dépasse l’intention initiale de ce tutoriel.
On peut observer la trace de ces containers qui ont terminé à l’aide de la commande :
hôte> docker ps --filter "status=exited"La commande docker ps permet d’obtenir la liste des exécutions en cours ou terminées de containers ainsis que des informations techniques associées. Ici on applique un filtre permettant de faire apparaître que les exécutions passées. On obtient un résultat comme :
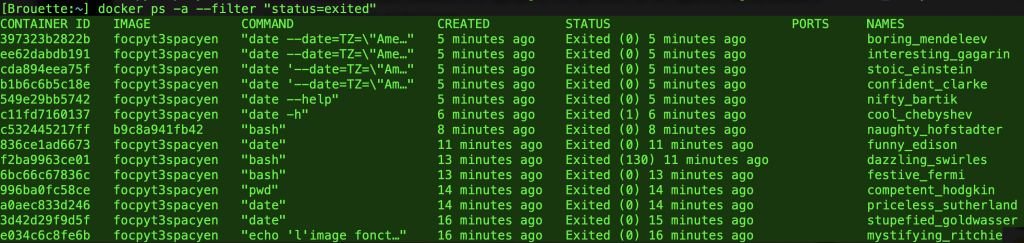
On notera que les containers sont aussi identifiés (afin de les contrôler, par exemple arrêter une exécution sans fin, etc), que l’image utilisée pour l’exécution est présente ainsi que la commande qui a été utilisée pour l’exécution interne, qu’on a une indication le moment de l’exécution, etc. La dernière colonne est un nom attribué automatiquement par docker pour identifier le container (à la manière des images qui sont identifiées par un numéro et un nom). On peut choisir soi-même le nom du container, mais ce n’est pas franchement utile à tout coup.
Pour exécuter une commande interactive il faut y ajouter un argument. Par exemple pour exécuter un shell (bash) dans le container et en obtenir le contrôle normal, on peut utiliser la commande :
hôte> docker run -it focpyt3spacyen bashDans ce cas on obtient en général un nouveau prompt (invitation à taper quelque chose), en effet le shell s’exécute dans un nouveau container et on en a le contrôle clavier :

La première ligne est interprétée par la machine standard et demande l’exécution interactive du shell bash dans le container obtenu. Celui-ci affiche alors un prompt qui lui est propre (root@c8a5eb7a5c48:/#) et on est invité à interagir avec lui. À partir de là et jusqu’à ce que ce shell soit terminé, les commandes sont exécutées dans le container! Essayons d’exécuter notre installation de python3 :
container> python3.9et l’on obtient bien le prompt de python :

Sortons de python par emploi de exit() puis du shell par exit. Le container termine et nous revenons sur la machine hôte.
Exécution d’un script
Il n’y a pas de difficulté particulière à exécuter un script, pourvu que l’image contienne les suites logicielles nécessaires. La difficulté réside dans l’injection du script à l’intérieur d’une image. En effet, les containers sont sévèrement confinés de sorte qu’ils ne voient pas la machine hôte, donc certainement pas ses fichiers, etc.
Heureusement Docker permet d’ouvrir les portes souhaitées, comme par exemple faire apparaître dans un container une partie des fichiers du système hôte.
Pour nous simplifier imaginons que l’on souhaite exécuter un script python qui lit une ligne dans un fichier de données et l’affiche à l’écran.
Voici le script python de nom myscript.py :
#!/usr/bin/env python3.9
print("Mon super script")
fo = open("foo.txt", "r")
print(fo.readline())
fo.close()Puis le contenu du fichier foo.txt :
bonjour au revoir
Pour (encore) simplifier l’exemple, on placera des ceux objets (le script et le fichier de données) dans un même répertoire, nommé test et pour l’exemple de nom complet /home/user1/workspace/test. De la sorte on va pouvoir faire apparaître le contenu du répertoire du système hôte (ici /home/user1/workspace/test) comme un répertoire dans un container :
hôte> docker run -it -v /home/user1/workspace/test:/toto focpyt3spacyen bashLa nouveauté sont les arguments -v /home/user1/workspace/test:/toto.-v permet d’indiquer que l’on souhaite créer un volume (un système de fichier partagé entre l’hôte et le container).
Sa valeur /home/user1/workspace/test:/toto permet d’obtenir sous le nom /toto dans le container le contenu du répertoire /home/user1/workspace/test. Attention, c’est bien un partage pas une copie! Toute modification d’un côté où de l’autre sera visible de l’autre partie.
Essayons de voir si l’export fonctionne :
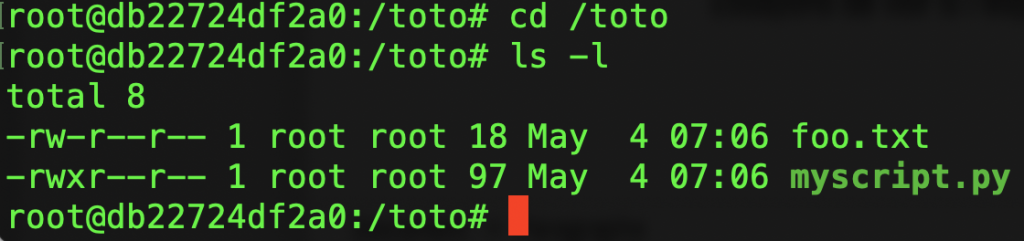
Oui, les fichiers du système hôte que l’on a partagés sont bien visibles!
Testons donc l’exécution du script dans le mode interactif du container :
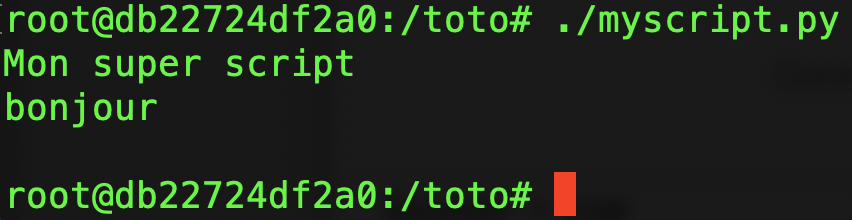
C’est gagné! Quittons l’exécution du shell par exit, cela termine le container.
Pourvu que l’on respecte dans l’esprit l’environnement de cet exemple, il peut alors se construire facilement des tas d’images diverses afin d’exécuter du code dans des environnements particuliers.